
Python based WLST tutorial is to present a detailed and descriptive introduction into regular expressions.
Every scripting language powered up with this regular expressions.
In scripting, Very complex problems can be resolved with simple regular expressions. If you are not aware of each expressions meaning then it would be Greek & Latin. You need to understand how they can be applicable then you can construct your WLST script in such a way that it could give a fantastic outcomes. A regular expression is that a set of possible input raw strings (includes alphanumerical, whitespaces, symbols).
Regular expressions descends from fundament concept in Computer Science called finite automata theory. A regular expression can match a string in more than one place.


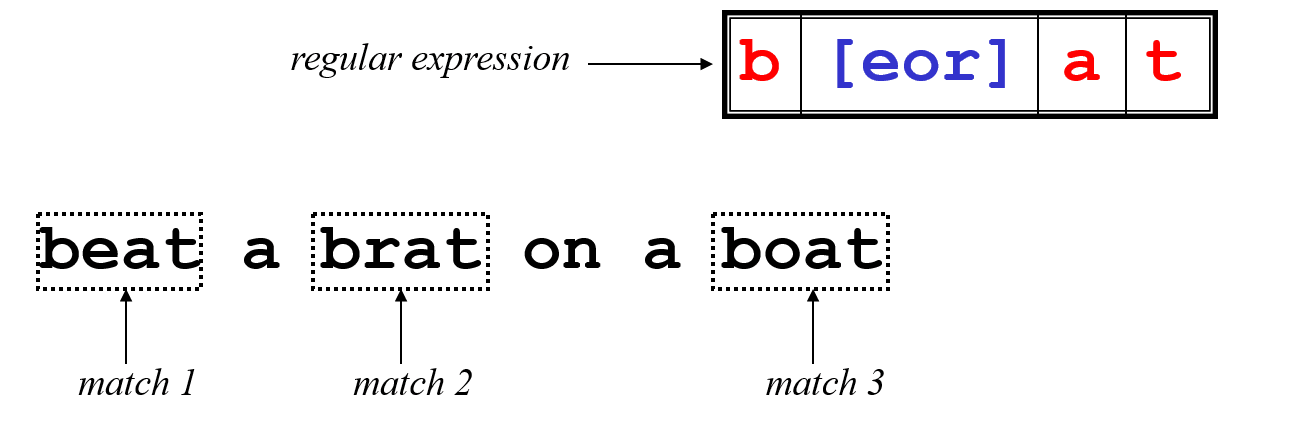
Here is the example to understand the expression that uses character class. The expression second char can be one of the three chars given in the char class [eor]. So the pattern matches three words from the given text.
[aeiou] will match any of the characters a, e, i, o, or u
[yY]es will match Yes or yes
Ranges can also be specified in character classes
[1-9] is the same as [123456789]
[abcde] is equivalent to [a-e]
You can also combine multiple ranges in the pattern
[abcde123456789] is equivalent to [a-e1-9]
Note that the hyphen - character has a special meaning in a character class but only if it is used within a range, if you use hypen at beginning its meaning changes it doesn't meant for range.
[-123] would match the characters -, 1, 2, or 3
Commonly used character classes can be referred to by name (alpha, lower, upper, alnum, digit, punct, cntrl)
Syntax [:name:]
[a-zA-Z] [[:alpha:]]
[a-zA-Z0-9] [[:alnum:]]
[45a-z] [45[:lower:]]
Important for portability across languages
re.I == re.IGNORECASE Ignore case
re.L == re.LOCALE Make \w, \b, and \s locale dependent
re.M == re.MULTILINE Multiline
re.S == re.DOTALL Dot matches all (including newline)
re.U == re.UNICODE Make \w, \b, \d, and \s unicode dependent
re.X == re.VERBOSE Verbose (unescaped whitespace in pattern
is ignored, and '#' marks comment lines)
Lets begin here...
 |
| Regular Expressions in WLST |
In scripting, Very complex problems can be resolved with simple regular expressions. If you are not aware of each expressions meaning then it would be Greek & Latin. You need to understand how they can be applicable then you can construct your WLST script in such a way that it could give a fantastic outcomes. A regular expression is that a set of possible input raw strings (includes alphanumerical, whitespaces, symbols).
Regular expressions descends from fundament concept in Computer Science called finite automata theory. A regular expression can match a string in more than one place.
Meta Characters in WLST
The special meaning for each symbol that we use in the regular expression. We have the following meta characters allowed in WLST.
Dot . in expression – any char
The . dot or period regular expression can be used to matches any character. Remember this don’t matches new line ‘\n’.The Character classes
Character classes [] can be used to match any specific set of characters.Here is the example to understand the expression that uses character class. The expression second char can be one of the three chars given in the char class [eor]. So the pattern matches three words from the given text.
Negate character class
Character class can be negated with ^ symbol inside the character class. That is [^].[aeiou] will match any of the characters a, e, i, o, or u
[yY]es will match Yes or yes
 |
| Negate Character class in re |
Ranges can also be specified in character classes
[1-9] is the same as [123456789]
[abcde] is equivalent to [a-e]
You can also combine multiple ranges in the pattern
[abcde123456789] is equivalent to [a-e1-9]
Note that the hyphen - character has a special meaning in a character class but only if it is used within a range, if you use hypen at beginning its meaning changes it doesn't meant for range.
[-123] would match the characters -, 1, 2, or 3
Commonly used character classes can be referred to by name (alpha, lower, upper, alnum, digit, punct, cntrl)
Syntax [:name:]
[a-zA-Z] [[:alpha:]]
[a-zA-Z0-9] [[:alnum:]]
[45a-z] [45[:lower:]]
Important for portability across languages
 |
| compile - search, match patterns on data |
import re
t="Demoadmin, demo_ms1, demo_ms2, my_clustr1"
p=re.compile('(d\w+)',re.I)
pos=0
while 1:
m=p.search(t, pos)
if m:
print "Now search start position :", pos
print m.group()
pos=m.end()
else:
break
 |
| Regular expression Compile pattern on search method |
Regular expression FLAGS
re.I == re.IGNORECASE Ignore case
re.L == re.LOCALE Make \w, \b, and \s locale dependent
re.M == re.MULTILINE Multiline
re.S == re.DOTALL Dot matches all (including newline)
re.U == re.UNICODE Make \w, \b, \d, and \s unicode dependent
re.X == re.VERBOSE Verbose (unescaped whitespace in pattern
is ignored, and '#' marks comment lines)
5 important re functions on WLST
There are few regular expression functions defined in the re module. Lets experiment with each one and see how they work.wls:/offline> dir(re) ['DOTALL', 'I', 'IGNORECASE', 'L', 'LOCALE', 'M', 'MULTILINE', 'S', 'U', 'UNICODE', 'VERBOSE', 'X', '__all__', '__doc__', '__file__', '__name__', 'compile', 'error', 'escape', 'findall', 'match', 'module', 'name', 'purge', 'search', 'split', 'sre', 'sub', 'subn', 'sys', 'template']
 |
| The re module methods and their functionality |
Lets begin here...
- The re.match() method The match() method works is that it will only find matches if they occur at the start of the string being searched.
- The re.split() method The re.split() method accepts a pattern argument. This pattern specifies the delimiter(s) with it, we can use any text that matches a pattern as the delimiter to separate text data. This is powerful to get the desired data from the text data.
wls:/offline> import re wls:/offline> str="WLST WebLogic wsadmin WebSphere" wls:/offline> mo=re.match(r'WLST',str) wls:/offline> mo.group(0) 'WLST'
clstrAddress="machine01.vybhava.com:8901,machine02.vybhava.com:8902"
wls:/offline> s=re.split(r"[:,]\d{4}",clstrAddress)
wls:/offline> s
['machine01.vybhava.com', ',machine02.vybhava.com', '']
- The re.search() method The following examples will illustrate how to search function with re module flags without it.
- The re.findall() method
The re.sub() method in WLST
One of the most important function in the re module is sub(). It works like 'find and replace'.
 |
| Split method samples in WLST |
import re
servers="admin, ms1, ms2, ms3, cluster1"
print re.split('\W+', servers)
print re.split('(\W+)', servers)
print re.split('\W+', servers, 2)
print re.split('\W+', servers, 3)
# The split mehtod works with multiple delimiters
e=os.environ['PATH']
for p in re.split(r':', e):
print p
#=====================================================================
# Created by : Manish K
# Updated by : Pavan Devarakonda
# Date : 20 Dec 2014
#=====================================================================
import re
s1 = "India is a country!"
s2 = "Delhi is the capital of India"
str = s1 + "\n" + s2
###### To Search first char in multilne
mo = re.search(r"^D[\w]*", str, re.M)
print "searched word with first char D:",mo.group()
###### To Search last char in multilne
mo1 = re.search(r"I[\w]*$", str, re.M)
print "Searched India:", mo1.group()
##### To match ignoring case
mo2 = re.search(r"india", str, re.I)
print "Ignore case:", mo2.group()
if re.search(r'[!@#$%^&*()]', str):
print "Some special Char found"
else:
print "Nothing special found"
print "Original str:", str
splitstr = re.split("\n", str)
print "split string with newline:",splitstr
## Optional Items
optSearch = "Find date Feb 2015, 12"
mo3 = re.search(r"Feb(ruary)? 2015", optSearch)
print "Optional search:", mo3.group()
## using +
mo4 = re.search(r"(Feb(ruary)?) ([0-9]+)", optSearch)
print "Search with + : ", mo4.group()
## unsing *
mo5 = re.search(r"[0-9].*", optSearch)
print "Using *", mo5.group()
### Grouping by the use of ()
gprStr = "Customer number: 232454, Date: February 12, 2015"
mo6 = re.search("([0-9]+).*: (.*)", gprStr)
print "Grouping with ():"
print mo6.group()
print mo6.group(1)
print mo6.group(2)
print mo6.groups()
Lets execute the above experiment on search function.
$ wlst search_re.py
Initializing WebLogic Scripting Tool (WLST) ...
Welcome to WebLogic Server Administration Scripting Shell
Type help() for help on available commands
searched word with first char D: Delhi
Searched India: India
Ignore case: India
Some special Char found
Original str: India is a country!
Delhi is the capital of India
split string with newline: ['India is a country!', 'Delhi is the capital of India']
Optional search: Feb 2015
Search with + : Feb 2015
Using * 2015, 12
Grouping with ():
232454, Date: February 12, 2015
232454
February 12, 2015
('232454', 'February 12, 2015')
When there is the need to find the multiple occurrences of a pattern in a text then findall() is the best function to use. This function returns a list of resulted strings.
Example on findall method in re module.
import re
line="WebLogic Automation course helps WebLogic Admins fish best opportunities"
print "words starts with A"
print re.findall(r"\bA[\w]*",line)
print "Find all five characthers long words"
print re.findall(r"\b\w{5}\b", line)
# Find all four, six characthers long words
print "4, 6 char long words"
print re.findall(r"\b\w{4,6}\b", line)
# Find all words which are at least 13 characters long
print "13 char"
print re.findall(r"\b\w{13,}\b", line)
Execution of the above example gives the output as follows:
$ wlst findallre.py Initializing WebLogic Scripting Tool (WLST) ... Welcome to WebLogic Server Administration Scripting Shell Type help() for help on available commands words starts with A ['Automation', 'Admins'] Find all five characthers long words ['helps'] 4, 6 char long words ['course', 'helps', 'Admins', 'fish', 'best'] 13 char ['opportunities']
sub(pattern, repl, string [, count=0])
This method replaces all occurrences of the re pattern in the given string with repl, substituting all occurrences unless max count provided. This method would return modified string as output.
#!/usr/bin/python import re DOB = "28-11-2003# This is DOB " # Delete Python-style comments num = re.sub(r'#.*$', "", DOB) print "DOB Num : ", num # Remove anything other than digits x = re.sub(r'\D', "", DOB) print "DOB without - : ", x # Substituting other symbol in anything other than digits FDOB = re.sub(r'\D', "/", num) print "DOB in new format : ", FDOBThis find and replacement experiment output
DOB Num : 28-11-2003 DOB without - : 28112003 DOB in new format : 28/11/2003
Hope this has given you some basic idea on re module usage in WLST shell. This can help you when you write a monitoring script and that will be given to reporting or graph designs on UI.
Extract hostname and IP from a String using re
Python gives us wonderful option to name the pattern which you are searching for. To make it possible ?P will be used in the searching pattern and within angular braces name will be defined.wls:/offline> s='www.vybhava.com=192.168.33.100' wls:/offline> hi=re.match(r'(?P[_a-z]\w*\.[_a-z]\w*.[_a-z]\w*)\s*=\s*(?P \d+\.\d+\.\d+\.\d+)',s) wls:/offline> hi.group('hostname') 'www.vybhava.com' wls:/offline> hi.group('ip') '192.168.33.100'
No comments:
Post a Comment
Please write your comment here